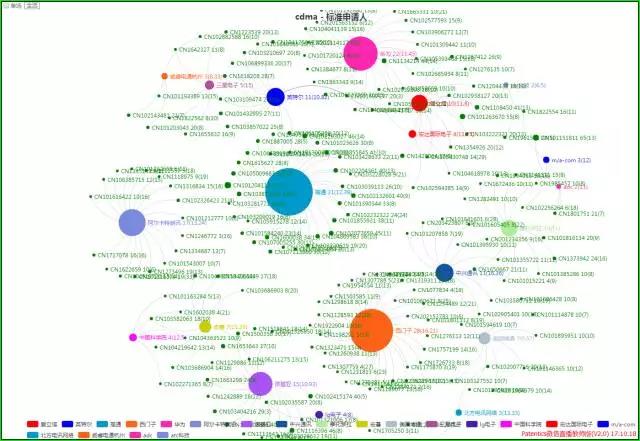
每一种颜色,每一个节点大小,每一个数字,每一条线,都包含着专利和专利相关的其它结构、非结构的关键信息。
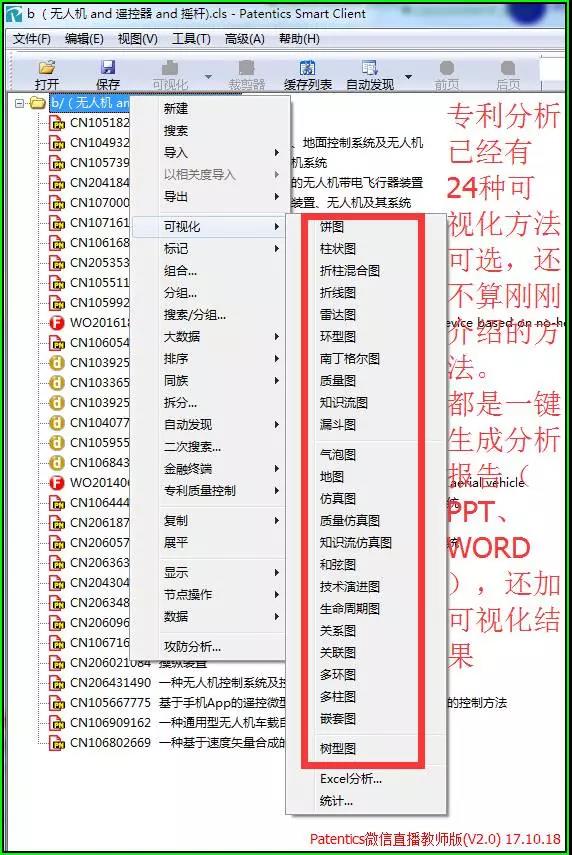
Patentics倡导的现代专利分析已经有24种可视化方法可选,还不算刚刚介绍的方法。全部都是一键分析、一键可视,再加一键生成图文并茂的专利分析报告,WORD、PPT可选。
这几天一直在考虑如何把可视化引入智能语义检索,即检索结果的可视化分析和可视化浏览文献,今天我们迈出了非常重要的一步。
今天要介绍的“专利知识(价值)谱计算及解读”。用全球最有价值专利为例。
还有一个看点值得关注,就是如何从任意一组专利文献中,通过Patentics流检索命令找出核心(基础)专利。而这些基础专利,往往都是该组(技术)的最有价值的文献。如果能从全世界专利文献中通过Patenti检索命令,找出最有价值的专利,从任意一组专利中找出最有价值的基础专利岂不更简单?
第一步,通过检索命令,检索全世界专利。
all/1 and db/all
全部数据库(db/all)中的全部专利文献(all/1)。

要找出这些全球专利文献中被引用最多的,同时按被引用次数多少排序,引用最多的,排在最前面。传统计算专利价值都按此方法做。
检索命令很简单,后加g/ref-d,
all/1 and db/all and g/ref-d
g/ref-d与传统检索命令不同,是变换检索命令,是对变换命令前的检索数据,进行变换计算。这里的检索数据是all/1 and db/all, 1亿2千万专利文献,变换命令,g/ref-d就是计算这1亿2千万文献的被引用次数。
输出结果,按被引次数多少排序,如下,
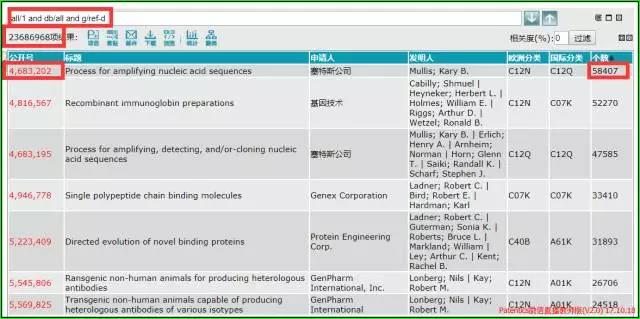
排在结果第一篇,US4,683,202,是被全球专利引用次数最多,的确是最有价值的专利。该发明专利(PCR)的发明人为此发明获1993年nobel生物医学奖。
大家都可以用自己的软件,看看该专利的被引用次数,Patentics是58407篇。
通过简单的检索式,找到了全球被引用最多,也就是全球最有价值的专利。如果希望了解某一技术领域,或者任意一组专利的被引用次数最多的专利文献,可以把all/1 and db/all换一下。比如说,
希望找到高通美国专利中被全球引用最多的专利,ann/高通 and db/us AND g/ref-d,

检索结果:全部高通的美国专利、申请中,共有28609篇专利、申请被全球专利文献引用(当然不是每篇都被引用的),如果计算高通全部美国专利、申请的总数,(ann/高通 and db/us),是45190篇,被引用率是 28609/45190。
排在第一位的专利,US5,103,459果然是高通的起家专利,CDMA的核心、基础专利。
就用这2篇已经被验证的最有价值专利,计算专利价值谱。
必须说明,Patentics的人工智能模型,只考虑该专利的文本内容,不考虑其它非文本信息,如著录项信息,包括引用、被引用数据。这里获取被引用数,纯粹是为了找出计算对象而已。
把这些专利号导入到客户端的分类器,导出到“Word”,选择“专利价值”,结果就出来。
由于计算量很大,输出需要几秒钟一篇。最后结果是,


每一个专利的价值谱,都有一个统计对比专利的价值谱,进行对比试验。对比专利的选择依据是,与被评估专利同一申请年,技术最相关的专利。从而复原该相关技术领域的当时竞争环境,即回答当时本领域的其他发明人正在实施的发明活动。
这2个原创专利的计算价值谱,果然是与众不同。先分析该2个专利的本身价值谱。大家一定注意到,这些专利的先知谱(红色阴影下),几乎为0,而后验谱(绿色阴影下)都很充分。表示这些原创发明的水平与当时的公知技术水平相比,几乎是“开天辟地”般的从0开始的原创性工作。
而从这些发明申请公开后,许多高相关度的专利开始出现,表示这些发明开始被本领域相关技术人员理解、改进、提高。
而这些提高、改进活动,都是受市场驱动,因此,绿线下的面积越大,本身预示着这些专利的市场价值越大。
可以把绿色阴影面积与被引次数等效起来。但是,通过计算生成的模型具有比人工引用更加客观、实时的优点。而且,模型一旦生成,具有预测能力,避免了人工引用产生的延迟效应。
通过对统计对比专利进行相同的价值谱计算,来复原当时的发明环境,计算本领域的技术人员正在从事本领域的发明的价值水平。
很显然,统计对比专利的发明人,在当时从事本领域相近的发明的水平,不属于开创性的基础发明,而是在现有技术上的改进,显著的红色阴影支持了这一结论。